Anyone else have problems with the Automox agents crashing on their endpoints?
Hi,
We’ve been a Automox client since May 2022.
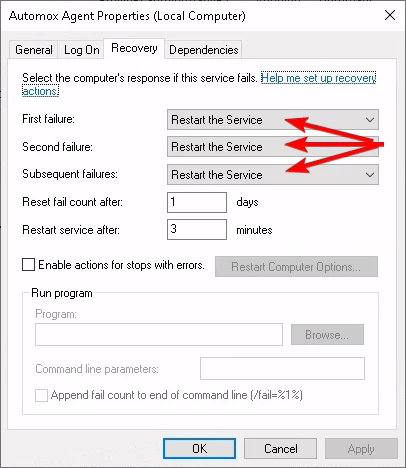
When we started to deploy the Automox Agent to our end user Windows 10 and 11 laptops we ran into a problem after about a month when a not insignificant amount stopped communicating with the Automox console. Without exception, when we investigated we found the Automox Agent wasn't running on the end point. Starting the service or restarting the machine would fix it.
Reviewing amagent.log would present messages about abnormal closure to websocket.
2022/09/25 00:54:07 stompclient.go:399: Error in axstomp readframe: websocket: close 1006 (abnormal closure): unexpected EOF 2022/09/25 00:54:07 stompclient.go:437: Consumer error: websocket: close 1006 (abnormal closure): unexpected EOF
We were told the root cause was because our end users connect to a corp VPN and that the momentary change in connectivity for those devices was causing the Automox agent to to crash. While I understood the logic, I felt the agent should be able to handle a change in connectivity more gracefully than simply dying.
This week I've discovered 100% of five newly deployed Debian Linux based VMs in a datacentre have also stopped communicating with the console. When checked, every one of them have the service stopped (technically it said Active/Exited). They all stopped on different days and times. Two of these machines were behind a content filtering proxy, three of them had direct internet connectivity. None of them were connecting to a VPN.
It feels to me as though the root cause is that the agent doesn't handle interruption to the websocket communication very well, and that instead of handling that situation in the agents code, they've chosen to rely on the the OS's ability to respawn the service.
Anyone experiencing similar issue or it it just me?
Page 1 / 1
I don’t know why this ended up in Community Worklets :|
Hello,
This sounds like you’ve encountered a technical troubleshooting scenario. I would suggest visiting our Customer Portal to open a support ticket so our engineers can help investigate.
You can click “Support Docs” on the top navigation bar of the Community forums or follow this link to access the Customer Portal: https://help.automox.com/hc/en-us
Be sure to log in to your account using the menu at the top right of the portal. If you’ve never used our portal before then you may need to through an initial registration.
Cheers, Brandon
Hi Brandon,
Thanks for taking the time to reply.
I have already visited the Customer Portal and I already have a ticket logged… two in fact #6852 and #4772.
This post was more about gauging if anyone else was having similar issues than getting the problem resolved.
Unfortunately as I only seem to be able to post to Community Worklets and Security News sections this post isn’t going to get the audience required to gauge that.
Regards
Steve
Hi Steve,
Thanks for the update! I’ve engaged our support team to look into your tickets further. We do appreciate the patience you are showing as the engineers investigate. We just released Agent 41 to start rolling out automatic agent upgrades yesterday (Tuesday, Sept 28th) that addresses some of the disconnect issues you’ve noted and we plan to have further fixes included in our next release in Q4 of this year.
As for why your post is showing in the Community Worklets section, I believe it is because of the code/script section. The system will automatically contain posts with code/script to those two categories.
Not to worry though, as we find most of our traffic in the Community Worklets section!
Cheers, Brandon
Yes, I regularly see devices with the Automox Agent service stopped. I have alerts setup from our monitoring agents to notify me so I can restart the service.
We had many servers having the same issue.
Unfortunately same for me, seems like users who often put there laptops to sleep and resume troughout the day experience the service failing to report back. I also opened a ticket and did not get anywhere.
Still experiencing agents crashing on our endpoints, some seems to be more affected than others. I see this error in the logs, and sometimes it results in the agent crashing and we have to manually restart it.
Still experiencing agents crashing on our endpoints, some seems to be more affected than others. I see this error in the logs, and sometimes it results in the agent crashing and we have to manually restart it.
Maybe something in our envirmemont thats intermittently cutting the connection as my logs showed something similiar. Do you use Netskope as well? We use it for traffic steering and filtering.
Still experiencing agents crashing on our endpoints, some seems to be more affected than others. I see this error in the logs, and sometimes it results in the agent crashing and we have to manually restart it.
Maybe something in our envirmemont thats intermittently cutting the connection as my logs showed something similiar. Do you use Netskope as well? We use it for traffic steering and filtering.
I don’t know what web filtering SW/HW the customer is using unfortunaly. I got this reply from Automox support regarding this issue.
So my thought is that the DNS/Web filter is not updating quick enough, so the agent is trying to reach api.automox.com on the old IP and because of this sometimes crashes.
I’m finding it really interesting that after I created this thread six months ago people are still posting their experiences about having the same problem. It gives me solace that I am not alone.
Our problems are largely stabilised.. not because the agent got any better, but because we’ve got other things monitoring if the Automox service has stopped and restarting it. In my opinion this isn’t a proper solution, but we didn’t really have much choice but to bodge it.
It beggars believe that the agents response to either not being able to connect to the Automox console OR having that communication interrupted is to crash, and then rely on the OS service managers to restart it. Is there no exception handling in the agent? I’ve never come across anything like it before in my twenty year career in IT.
I think I’m going to have to put a lot of thought into whether or not to renew our license with Automox this year.
I’m finding it really interesting that after I created this thread six months ago people are still posting their experiences about having the same problem. It gives me solace that I am not alone.
Our problems are largely stabilised.. not because the agent got any better, but because we’ve got other things monitoring if the Automox service has stopped and restarting it. In my opinion this isn’t a proper solution, but we didn’t really have much choice but to bodge it.
It beggars believe that the agents response to either not being able to connect to the Automox console OR having that communication interrupted is to crash, and then rely on the OS service managers to restart it. Is there no exception handling in the agent? I’ve never come across anything like it before in my twenty year career in IT.
I think I’m going to have to put a lot of thought into whether or not to renew our license with Automox this year.
Upper management is thinking the same thing, Automox isnt exactly cheap software. Lots of competition out there, support is often dismissive and lacking I find.
1,000 times yes. We have been experiencing the same issue and it is increasing in scale. Automox’s solution was to create a worklet that creates a scheduled task, which makes the PC restart the agent every hour - this is not a solution imo, it’s a band-aid, and with how many others I hear discussing this issue, it’s concerning. We started experiencing a wide array of issues immediately after we onboarded, and just haven’t seen the light at the end of this tunnel, unfortunately.
Automox has just become extremely unreliable for a patching solution - I don’t think it was ever meant to be deployed on a large scale, despite them marketing the product as enterprise, it clearly isn’t. Unfortunately we didn’t have the man power or time to look into alternative solutions before our renewal, so we have another year, but we will certainly be migrating to another solution after.
Hi @Nvlddmkm,
If you haven’t already, let’s get a Support ticket issued for this! The behavior that you are experiencing is not normal, and the Support team can help assist with narrowing down the root cause and coming to a solution. I’d also recommend looping in your Customer Success Manager so they can help guide the resolution.